Technological Issues: The biggest problem with hearing to podcasts is that due to limited bandwidths (which is the case with majority of the users). The podcast is not heard as a smooth, uninterrupted recording, but heard in chunks of 3-4 seconds. Hearing to such short bursts, and that too in a foreign accent, makes most podcasts utterly incomprehensible, and an irritating User Experience.
Instead, if these podcasts are buffered somewhere on the Client side, and delivered in chunks of say, 1 min, or 5 mins (decided by the user), it would be a much more satisfying experience. And while the user is listening to the first chunk, the next chunk simultaneously gets loaded. The user would be willing to wait for a brief period of time, if he gets a seamless experience later. In its present state, only the few podcasts in the popular category ( which are stored in the cache on Yahoo servers) offer a certain degree of seamlessness.
Even if a user does not listen to the Podcast directly from the website, and decides to download it, he or she would like to listen to a few minutes of recording atleast, to decide whether he would like to download it or not.
Usability Issues:
Rating:
Most Popular :
This category does not make it evident to the user, about what is the basis of this popularity, and on what basis are the results sorted. Is the popularity on the basis of no. of subscribers, no. of downloads or what?
 Highly Rated:
Highly Rated:
Same is the problem with this category. Firstly, the results are not sorted on the basis of ratings, and secondly, almost all the podcasts in this category have a five star rating. So, a user does not know on what basis are these podcasts sorted. Probably, the no. of users which have rated the podcast ( and thus contributed to the overall average rating) would be a good measure of the reliability of the rating, and a good yardstick to sort the results.
Podcasts within a particular category:
Again, within a category, its not clear on what basis are the Podcasts sorted. They don’t seem to be on the basis of ratings, or no. of subscribers or any other popularity parameter.
Rating of Series:
Its not evident how does the rating system of the podcasts work. Whether or not the rating for a series is affected by the rating of its individual episodes. If yes, than how?
Content:
Information about the content of the podcast:
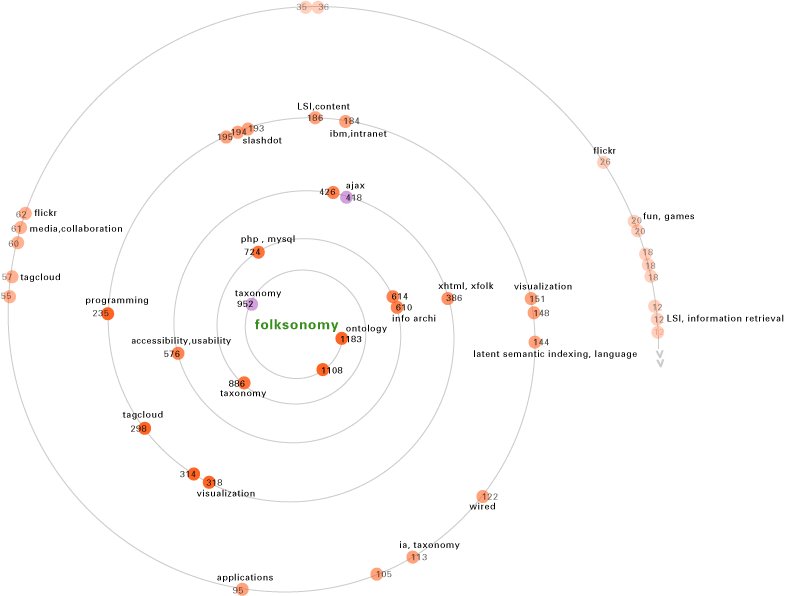
 All the podcasts have a few words from the Introductory line, to tell the user what the podcast is about. In most cases, these few words are totally meaningless and superficial and don’t convey the information about the content at all. Instead,tags allocated by the listeners to the podcast give much more relevant info about it in just as many words. So, probably, the top 5 tags for that podcast would be much more effective in conveying its content.
All the podcasts have a few words from the Introductory line, to tell the user what the podcast is about. In most cases, these few words are totally meaningless and superficial and don’t convey the information about the content at all. Instead,tags allocated by the listeners to the podcast give much more relevant info about it in just as many words. So, probably, the top 5 tags for that podcast would be much more effective in conveying its content.
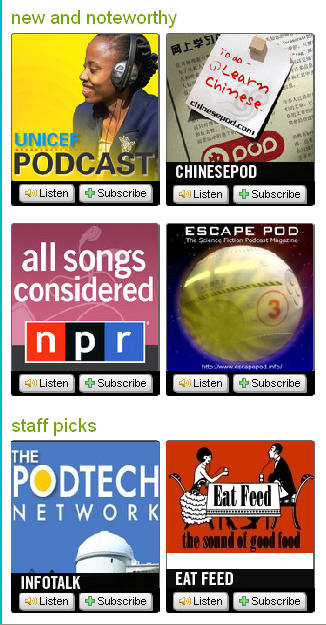
Same is the case with the Podcasts in the ‘new and noteworthy’ and ‘staff picks’ categories. The big promotional images for the podcasts tell nothing about their content and only add to visual clutter.
Tagging of Podcasts:
Along with putting all the Tags for a series together as one cluster, it would also be helpful to give the tags associated with each episode along with the episode, to know which specific episode has that content specified by the tag.
Thus the system should allow putting not only series specific, but episode specific tags as well, which would be a more efficient way of tagging as far as searchability of content is concerned.
Accessing of specific content within the Podcast:
As the no. of episodes within a series increases (already a few series have more than 100 episodes), it would be convenient to allow searching for a particular tag (from within the cluster of tags assigned to the entire series), within a series itself and kind of filter out only those episodes from a series which have that tag.
Further, many podcasts are over 1-2 hours long. How to search for specific content within the episode is an issue which needs to be addressed. Probably the episodes need to be Time-tagged i.e. tagged along the timeline, with the episodes divided into smaller chunks according to the content. Further, the first few seconds of each such chunk can also be combined together to kind of form the Headlines or Highlights of the podcast, just like in any news show on TV. The user can then just listen to these Headlines to get a brief summary of the Podcast, and then choose to hear or download the full Podacst, or specific chunks of it.
Scalability of the System:
As more and more users start tagging the Podcasts, there would be tremendous pollution in the Tag Library, simply because tagging in its present form is a free text entry kind of system, where any user can give any tag. So synonyms, acronyms, misspelt tags etc. will become major hinderances to searchability of information and reduce the effectiveness of the system unless accounted for. This problem will worsen for systems like Yahoo Podcast which allow multi word tags than systems like del.icio.us ( a social bookmarking tool), which only allow single word tags.
For ex., tags like ‘Tech’ and ‘Technology’ are very similar, as tech is an acronym of technology. But when a user searches for all podcasts about ‘technology’ (in reality, all podcasts about ‘tech’ and ‘technology’), he only gets podcasts tagged with ‘technology’ and not ‘tech’.
Thus, the challenge is how to make the system realize that synonyms like ‘movie’ and ‘film’ , acronyms like ‘technology’ and ‘tech’ and singular and plurals like ‘computer’ and ‘computers’ are similar and therefore the podcasts tagged by such tags are also displayed in the search results.